Das HyperText Transfer Protocol (HTTP) ist ein Anwendungsprotokoll, das vorallem durch seine Verwendung in dem Internet-Dienst World Wide Web bekannt geworden ist. Das Protokoll beschreibt den Austausch von Nachrichten zwischen einem Client und einem Server und ist keineswegs auf das World Wide Web beschränkt. 2015 wurde die derzeit aktuelle Version HTTP/2 mit dem RFC 7540 veröffentlicht. Immer noch weit verbreitet ist die Version HTTP/1.1, die seit 1999 verwendet wird. Alle Protokollversionen arbeiten mit TCP als Transportprotokoll, also mit Stream Sockets. Da sich die zweite Übungsaufgabe mit HTTP (und der Socketschnittstelle) beschäftigt, wird dieses Protokoll hier etwas umfangreicher dargestellt, als die anderen Anwendungsprotokolle, allerdings ausschließlich im Rahmen des World Wide Web.
Ursprünglich wurde HTTP entwickelt, um im Rahmen des World Wide Web HyperText-Dokumente zu übertragen. Das sind Daten, die durch eine Dokumentenbeschreibungssprache, hier durch die HyperText Markup Language (HTML), beschrieben werden. Die Grundlagen für das praktische Arbeiten mit HTML werden im Folgenden als aus dem Grundstudium bekannt vorausgesetzt.
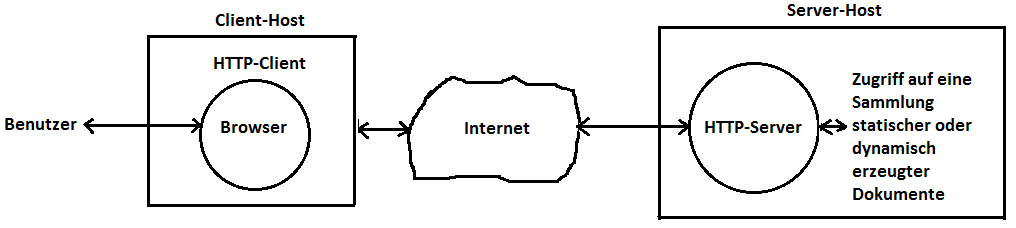
Die durch HTTP beschriebene Kommunikation folgt wie bereits erwähnt einem Client/Server-Modell, wobei die Clients üblicherweise als Browser angelegt sind. Mit ihnen kann in verzeigerten Dokumentenstrukturen geblättert werden, die von Servern bereitgestellt werden. Die Dokumente, die ein Server verwaltet, müssen keineswegs statisch sein, sondern können erst zur Laufzeit entstehen, also dynamisch sein. Die folgende Grafik zeigt die Architektur des Nachrichtenaustauschs:
Zwischen den Clients und den Servern im World Wide Web werden zwei Arten von Nachrichten ausgetauscht:
Jede HTTP-Nachricht, ob Request oder Response, ist zweiteilig. Sie besteht aus einem Header (Kopfteil) und aus einem Body (Rumpfteil), der leer sein kann.
Der HTTP-Header ist zeilenorientiert, wobei unter einer Zeile eine Zeichenfolge verstanden wird, die genau ein NewLine-Zeichen enthält, und zwar an ihrem Ende. Die erste Zeile des Headers enthält eine Aktionsangabe, alle anderen enthalten Metadaten zu dem Übertragungsvorgang. Dazu gehören Angaben zur jeweiligen Rechnerumgebung, zum Umfang der Übertragung und zur Kodierung der Daten im Rumpfteil der Nachricht. Alle Headerzeilen außer der ersten sind als Schlüssel/Wert-Paare aufgebaut, wobei als Trennzeichen zwischen Schlüssel und Wert ein Doppelpunkt gesetzt wird, dem ein oder mehrere Leerzeichen folgen können. Die Anzahl dieser Zeilen ist nicht festgelegt. Zwei direkt aufeinander folgende NewLine-Zeichen beenden den HTTP-Header. Das heißt, dass die erste Leerzeile im Header sein Ende anzeigt.
Ein Request sieht beispielsweise folgendermaßen aus:
Diese Nachricht besteht nur aus einem Header. Sie hat keinen Rumpf. Nicht sichtbar ist im Beispiel, dass es eine vierte Zeile gibt. Sie ist leer und schließt den Header ab. In der ersten Zeile steht die Aufforderung an den Server, dem Anfrager eine bestimmte Ressource zu senden (GET). Im Beispiel zeigt der Schrägstrich zwischen dem GET und der HTTP-Versionsnummer an, dass die Web-Leitseite des Serverrrechners angefordert wird. In der zweiten Zeile gibt der Client an, dass er den Server am Port 80 des Rechners namens public.bht-berlin.de ansprechen will. Und in der dritten Zeile teilt der Browser dem Server mit, dass er HTML-Seiten entgegennehmen kann. Das Beispiel ist eine Verkürzung des tatsächlichen Aussehens eines Requests. Üblicherweise gibt es noch eine ganze Reihe weiterer Zeilen mit Angaben zum Übertragungsvorgang.
Das Folgende ist eine ebenfalls verkürzt dargestellte Response-Nachricht:
Diese Nachricht besteht aus einem Header und einem nichtleeren Body. Man beachte auch hier die Leerzeile (Zeile 4), die den Header abschließt. In der ersten Zeile teilt der Server dem Client nach der HTTP-Versionsangabe mit, dass er dessen Request erfolgreich (200 OK) bearbeiten konnte. Die nächsten beiden Headerzeilen sagen aus, dass der Body aus 18 Bytes besteht, die als UTF-8-kodierte HTML-Seite ankommen werden. Der Rumpfteil der Nachricht enthält diese HTML-Seite (18 Bytes).
Einer HTTP-Nachricht stehen keinerlei Informationen aus vorangegangenen Nachrichten zur Verfügung. Man sagt dazu, das Protokoll sei zustandslos. Aber HTTP legt fest, dass der Nachrichtenaustausch zwischen einem Client und einem Server in Form eines Frage/Antwort-Spiels zu erfolgen hat, bei dem der Server darauf wartet, von einem Client angesprochen zu werden. Ein Kommunikationszyklus (ein Frage/Antwort-Zyklus) verläuft folgendermaßen:
Erst dann, wenn ein solcher Kommunikationszyklus beendet ist, kann ein neuer erfolgen. Diese HTTP-Festlegung eines Frage/Antwort-Spiels zwischen Client und Server ist für manche Anwendungen hinderlich. Man denke an die Übertragung einer Bilderfolge im Rahmen einer HTML-Seite. Deshalb ist es ab der HTTP-Version 1.1 möglich, dass ein Client den Server im Request-Header mit der Angabe
bitten kann, von dem voreingestellten Kommunikationszyklus abzuweichen und eine Folge von Responses zu schicken ohne jeweils auf einen neuen Request zu warten. Der Server kann der Bitte nachkommen und seinerseits im Response-Header mit
sein Akzeptieren angeben. Oder er verweigert sich in seiner Antwort mit
Dann muss der Client bei dem vorgegebenen Frage/Antwort-Spiel bleiben.
HTTP definiert versionsabhängig mehrere (bei HTTP/1.1 insgesamt 9) Anforderungen (Requests), die ein Client an einen Server herantragen kann. Die Art der Anforderung wird in der ersten Zeile der Nachricht als erste Zeichenkette angegeben. Ihr folgt, durch ein Leerzeichen getrennt eine Pfadangabe, die sich auf das Dateisystem des Serverrechners bezieht. Dort ist ein bestimmtes Verzeichnis ServerRoot genannt worden. Die Pfadangabe wird vom HTTP-Server relativ zu diesem Verzeichnis interpretiert. Der Pfadangabe folgt ein Leerzeichen, an das sich die HTTP-Versionsnummer der zugrundeliegenden Version anschließt. Damit ist die erste Zeile beendet.
Mit den HTTP-Requests können Downloads von Dateien (Webseiten) angestoßen (GET- und POST-Requests), aber auch per Upload (PUT-Requests) Dateien zum Server übertragen werden. Unter anderem ist es auch möglich, Dateien beim Server zu löschen (DELETE-Requests). Im Rahmen dieses Abschnitts sollen aus Platzgründen lediglich der GET- und eingeschränkt der POST-Request näher betrachtet werden.
In der ersten Zeile seiner Antwortnachricht beschreibt der Server, wie er mit dem zugehörigen Request umgegangen ist. Die erste Response-Zeile beginnt mit der Versionsnummer der verwendeten HTTP-Version, der ein Leerzeichen folgt. Daran schließt sich ein Statuskode an, dem, durch ein Leerzeichen getrennt, eine Verbalisierung dieses Kodes folgt. Damit ist die erste Zeile abgeschlossen.
Der Statuskode ist dreistellig und numerisch. Die erste Ziffer zeigt eine Bearbeitungskategorie an, die anderen beiden sind Verfeinerungen. Aus Zeitgründen sollen nicht alle Statuskodes vorgestellt werden. Es reicht, darauf hinzuweisen, dass eine Angabe der Form
(mit zwei Ziffern an der Stelle von xx) eine erfolgreiche Bearbeitung des eingegangenen Requests signalisiert, während
auf einen Fehler des Clients und
auf einen des Servers hinweisen. Einige wenige Beispiele für erste Response-Zeilen sollen hier genügen:
Das World Wide Web ist ein verteiltes Dokumentensystem. Entstanden ist der Dienst 1989 am CERN in Genf. Später wurde er von der Internet Engineering Task Force (IETF) und dem World Wide Web Consortium (W3C) standardisiert. Anstatt vom World Wide Web spricht man oft kurz vom Web.
Eine Seite im Web, allgemeiner gesagt eine Ressource im Web, wird durch eine Uniform Resource Locater (URL) identifiziert und lokalisiert. (Der weibliche Artikel für URL hat sich im Deutschen durch die Anlehnung an das Wort Adresse weitgehend durchgesetzt.) Der genaue Aufbau einer URL ist komplex und soll hier nicht vertieft werden. Im Folgenden wird es immer wieder Beispiele dazu geben.
Den Verzeigerungen, die hier Hyperlinks oder kurz Links heißen, in HTML-Dokumenten sind URLs zugeordnet, die in den in den HTML-Seiten sichtbaren Linkbezeichnungen nicht zum Ausdruck kommen müssen. Der Web-Benutzer arbeitet mit diesen Linkbezeichnungen und lädt dadurch Ressourcen wie beispielsweise HTML-Seiten ohne die zugehörigen Dateien kennen und lokalisieren zu müssen. Trotz der weltweiten Verteilung der Dokumente hat der Benutzer den Eindruck, er arbeite mit einem einzelnen, kohärenten System.
Ein Browserbenutzer kann mit seinem Browser nicht jeden möglichen HTTP-Request auslösen, sondern ist auf PUT- und POST-Requests beschränkt. Ein Browser-Request erfolgt direkt oder indirekt (programmgesteuert) durch eine Benutzereingabe. Im Wesentlichen gibt es dafür folgende Möglichkeiten.
Jetzt soll kurz auf den Unterschied zwischen einem GET- und einem POST-Request eingegangen werden. Mit beiden Requests wird eine Ressource (meist eine Webseite) angefordert. In einem HTML-Eingabeformular gibt es einen Parameter namens method. Je nachdem, ob method=get oder method=post angegeben wird, entsteht der entsprechende Request.
Ist es ein GET-Request, dann werden die an den Server zu sendenden Daten als Teil des HTTP-Headers übertragen. Ist es ein POST-Request, dann bilden sie den Datenteil des entstehenden HTTP-Pakets. Mit den beiden folgenden Beispielen und ihrer Auswertung wird dieser Sachverhalt verdeutlicht.
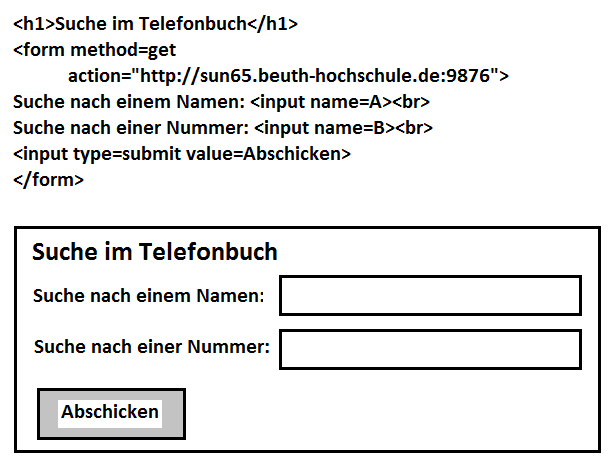
Das Beispiel, das auch als Hinweis auf die zweite Übungsaufgabe dienen soll, zeigt nicht die gesamte HTML-Seite, sondern lediglich als Auszug ein HTML-Eingabeformular mit einer Überschrift, zwei Labels mit je einem Eingabefeld und einem Submit-Button. Zunächst wird der HTML-Kode angegeben, anschließend das optische Erscheinungsbild. Im Form-Tag wird ein GET-Request formuliert, der per HTTP an einen Rechner namens sun65.bht-berlin.de gerichtet ist, an dessen Port 9876 ein HTTP-Server erwartet wird. Man beachte, dass die beiden Eingabefelder jeweils einen Namen (A bzw. B) erhalten haben, während der Submit-Button namenlos geblieben ist.
Für das zweite Beispiel wurde eine HTML-Form benutzt, die zu einem identischen Erscheinungsbild führt wie die erste. Der zugehörige HTML-Kode unterscheidet sich von dem des ersten Beispiels lediglich an einer einzigen Stelle. Im ersten Beispiel hat der method-Parameter im Form-Tag den Wert get, beim zweiten post. Wegen des völlig identischen Aussehens der beiden HTML-Formulare auf dem Bildschirm wird beim zweiten Beispiel nur der HTML-Kode angegeben:

Beim Senden von Formulardaten, und zwar unabhängig davon, ob ein GET- oder ein POST-Request formuliert worden ist, erzeugt der Browser aus den Eingabedaten des Formulars zunächst einen String der folgenden Form:
Die Feldnamen sind die Namen der jeweiligen Eingabefelder des HTML-Formulars. Aufgenommen werden nur die Felder, die in der HTML-Form einen Namen erhalten haben. Der String, der dadurch entsteht, heißt Query String. Angenommen, der Benutzer füllt eines der beiden oben angegebenen Beispielformulare aus, indem er als zu suchenden Namen Meier und als Nummer 4711 eingibt und dann den Abschicken-Button betätigt, dann entsteht in beiden Fällen der Query String
Lässt er das Nummernfeld frei und übermittelt nur den Namen Meier, dann entsteht der String
Lässt er beide Felder leer und schickt das leere Formular ab, dann lautet der Query String
Ein HTTP-Server, der einen GET- oder POST-Request erhält, muss diesem den Query String entnehmen, ihn mit Hilfe der Trennzeichen & und = zerlegen und mit Hilfe der Feldnamen eine Zuordnung der Werte vornehmen.
Wird in einem HTML-Eingabeformular ein GET-Request gefordert, dann wird der Query String durch einen Schrägstrich und ein Fragezeichen getrennt an die, im action-Parameter des Form-Tags angegebene URL angefügt. Diese wird dann als erweiterte URL bezeichnet. Beispielsweise führt der Query String
im obigen Beispiel zu der folgenden erweiterten URL, die auch im URL-Eingabefenster des Browsers angezeigt wird:
Ihr kann das Browserprogramm entnehmen, zu welcher Anwendung (Portnummer) auf welchem Host er eine Stream-Socketverbindung aufbauen soll, und welcher GET-Request in den Socket zu schreiben ist. Im Beispiel schreibt er als erste Zeile in den Socket
Die Sichtbarkeit des Query Strings im Browserfenster bei GET-Requests führt zu der Sicherheitsempfehlung, keine Daten aus HTML-Forms mit Passwort-Eingabefeldern als GET-Request zu übertragen. Es wäre übrigens trügerisch, sich bei POST-Requests bei Passworteingaben sicher zu fühlen, denn der Browser verschlüsselt den Query String nicht. Jeder Sniffer, wie beispielsweise WireShark, kann die Requests, egal ob GET oder POST, im Klartext lesen.
Sollen die Daten aus einem HTML-Eingabeformular als POST-Request gesendet werden, dann entsteht keine erweiterte URL und aus dem aus der im Formular angegebenen Ziel-URL abgeleiteten Socket wird ein POST-Request geschrieben. Der Query String wird dann zum Datenteil der entstehenden HTTP-Nachricht, die - wieder etwas verkürzt dargestellt - folgendermaßen aussieht:
Man beachte wieder die Leerzeile, die den HTTP-Header abschließt.
Ein Query String darf, gleichgültig, ob ein GET- oder ein POST-Request vorliegt, keine Sonderzeichen, insbesondere keine Wortlücken, enthalten, denn Letztere sind Trenner. Der Query String wird deshalb vom Browser, bevor er in eine Request-Nachricht eingebracht wird, nach folgender Vorschrift kodiert:
Beispielsweise wird ä in %e4 umgewandelt und + in %2b. Wird in eines der beiden Beispielformulare als Name von Hänschen eingetragen (und keine Nummer), dann entsteht beim Abschicken der Formulardaten der Query String
Ein HTTP-Server erhält einen Query String von einem Browser entweder über einen GET- oder einen POST-Request. Es ist gleichgültig, wie er ihn erhält, er muss die Query-String-Kodierung rückgängig machen. Bei der zweiten Übungsaufgabe muss das von den Studierenden zu erstellende Programm, also der Telefonserver, diese Dekodierung leisten. Java stellt in seiner Klasse URLDecoder dafür eine hilfreiche Methode zur Verfügung:
Sicherheitsbelange haben dazu geführt, dass eine HTTP-Erweiterung namens HTTP-Secure (HTTPS) entwickelt wurde, die zwischen HTTP und dem Transportprotokoll TCP eine Verschlüsselungsschicht einschiebt. HTTPS steht seit 1994 zur Verfügung und ist weit verbreitet.