Als erstes der beiden Internet-Transportprotokolle soll das User Datagram Protocol (UDP) vorgestellt werden, das einen verbindungslosen Datagrammdienst realisiert. Ein Datagrammtransport heißt verbindungslos, wenn aus einem Datagramm nicht abgeleitet werden kann, welches als nächstes zu transportieren bzw. zu erwarten ist. Entwickelt wurde UDP ab 1977 mit dem Ziel, im Internet ein schlankes Transportprotokoll zur Verfügung zu haben. Dies wird erreicht, indem der mit dem Protokoll verbundene Verwaltungsaufwand sehr klein gehalten wird. UDP wurde 1980 im RFC 768 definiert.
Der Datentransport mit UDP ist zwar schnell, jedoch nicht oder kaum gesichert. Das Protokoll folgt einem Peer-to-Peer-Modell, und jede Anwendung, die es benutzen will, muss ihre Daten in Datenpaketen, sogenannten Benutzerdatagrammen, mit einem vorgeschriebenen Aufbau zusammenfassen. In Java bieten die Klassen DatagramSocket und DatagramPacket eine Programmierschnittstelle zu UDP. Im Abschnitt 2.2.3 (Java Datagram Sockets) ist der praktische Umgang mit den beiden Klassen bereits gezeigt worden.
Ein Benutzerdatagramm besteht aus einem Kopfteil (Header) und einem Datenteil (Body), und es wird unabhängig von allen anderen auf der sendenden Seite an den Transportdienst übergeben und auf der empfangenden Seite aus ihm entgegengenommen. Beim Transport von Benutzerdatagrammen durch UDP gibt es für Benutzerdatagramme
Die Aufgabe von UDP besteht einzig und allein darin, Benutzerdatagramme der richtigen Anwendung zuzustellen, wobei in Kauf genommen wird, dass dies nicht immer korrekt gelingt.
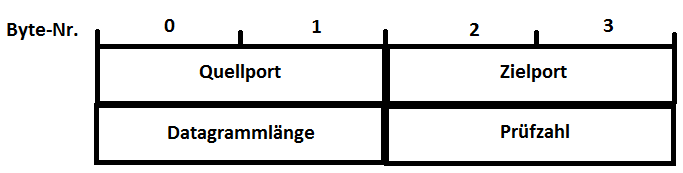
In dem Kopf (Header) eines Protokolls werden Informationen zusammengestellt, die notwendig sind, um das zugehörige Datenpaket protokollgerecht zustellen zu können. Für UDP sind dies im Wesentlichen die Portnummern der jeweiligen Sender- bzw. Empfängeranwendung, was die Aufgabe des Protokolls widerspiegelt. Der UDP-Protokollkopf hat eine feste Länge von 8 Bytes und ist in vier Felder aus je 2 Bytes eingeteilt. Üblicherweise werden Protokollköpfe in grafischen Darstellungen reihenweise mit Reihen aus jeweils 4 Bytes (32 Bits) präsentiert. Die folgende Grafik folgt dieser Gepflogenheit und zeigt den Aufbau des UDP-Headers:
Der Protokollkopf enthält lediglich die beiden Ports von Sender (Quellport) und Empfänger (Zielport), eine Längenangabe und eine optionale Prüfzahl, auf deren genaue Berechnung hier nicht näher eingegangen werden soll. Es soll genügen, festzuhalten, dass die Prüfzahl
umfasst. Dass die Prüfzahl als optional bezeichnet wird, bedeutet, dass auf ihre Angabe auch verzichtet werden kann, denn die meisten UDP-Anwendungen werten sie nicht aus. Die Längenangabe schließt den Protokollkopf mit ein und wird in Bytes angegeben, so dass durch die Feldlänge von 16 Bits ein Benutzerdatagramm auf eine Größe von 65.535 Bytes begrenzt ist. Anwendungsprogramme müssen dies berücksichtigen.
Der kleine Protokollkopf von UDP und die gar nicht oder kaum vorhandene Sicherung des Datentransports verursachen nur einen geringen Verwaltungsaufwand, so dass UDP ein sehr schnelles Protokoll ist. Eine UDP-Anwendung muss gegenüber Datenverlusten und veränderten Reihenfolgen der Benutzerdatagramme unempfindlich sein oder sie muss selbst entsprechende Sicherungsmaßnahmen durchführen.
Für Anwendungen wie beispielsweise Dateiübertragungen ist UDP nicht gut geeignet. Dateien sind meist zu groß für ein einziges Benutzerdatagramm, so dass die Aufteilung in mehrere Datagramme, verbunden mit entsprechenden Sicherungsmaßnahmen Aufgabe der Anwendung ist. Dennoch gibt es für das Internet ein solches Tool. Es heißt Trivial FTP (TFTP), realisiert einen File Transfer mittel UDP und hat in lokalen Netzwerken eine gewisse Verbreitung gefunden.
UDP wird hauptsächlich von Multimediaanwendungen eingesetzt. In diesem Umfeld ist es nicht entscheidend, ob alle Benutzerdatagramme beim Empfänger ankommen. Gehen einige verloren, vermindert dies zwar die Qualität einer Sprachausgabe oder einer Videoübertragung, aber die gesamte Übertragung wird nicht gefährdet. Weitere typische Anwendungen für UDP sind RPC-Aufrufe und DNS-Anfragen. Hier passen die zu übertragenden Daten jeweils in ein einziges Benutzerdatagramm, so dass es einfacher ist, bei einem Datenverlust den Vorgang zu wiederholen anstatt aufwändige Sicherungsmaßnahmen zu ergreifen.