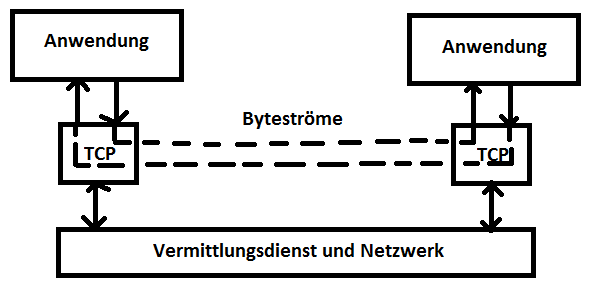
Das zweite Internet-Transportprotokoll, das betrachtet werden soll, ist das verbindungsorientierte Transmission Control Protocol (TCP). Ein Protokoll heißt verbindungsorientiert, wenn aus einer Transporteinheit abgeleitet werden kann, welche als nächste zu transportieren bzw. zu erwarten ist. TCP ist etwas älter als UDP und wurde ab 1973 erprobt. 1981 erfolgte mit dem RFC 793 die Standardisierung. TCP stellt Anwendungsprogrammen einen Datenstromdienst (Stream Service) zur Verfügung. Zwischen zwei Anwendungen wird eine Verbindung aufgebaut, über die dann Daten in Form von Bytefolgen in einem Vollduplex-Betrieb ausgetauscht werden können. Die folgende Grafik soll diesen Sachverhalt verdeutlichen:
Anschaulich realisiert TCP eine bidirektionale Pipeline zwischen zwei Anwendungen, durch die gegenläufig zwei voneinander unabhängige Byteströme fließen können, was in der Grafik durch die gestrichelten Linien angedeutet werden soll.
TCP sichert den von einer Anwendung kommenden, also den zu sendenden, Bytestrom durch ein Bestätigungsverfahren. Dazu teilt die sendende TCP-Station diesen Bytestrom, dessen Ende für sie ja nicht absehbar ist, in Pakete ein. Für jedes Paket berechnet sie eine Prüfzahl, die von der empfangenden TCP-Station kontrolliert wird.
Die Bytes des von einer Anwendung kommenden Bytestroms werden von der sendenden TCP-Station durchnummeriert. Falls die Bytes korrekt und lückenlos übertragen werden konnten (und auch nur dann), bestätigt die empfangende TCP-Station den Erhalt von Anwendungsdaten. Und zwar bestätigt sie den Erhalt von Bytes, nicht den von Segmenten. Stellt sie einen Prüfzahlfehler fest, unterlässt sie die Bestätigung. Und selbstverständlich kann sie auch keinen Erhalt von Daten bestätigen, die verloren gegangen sind. Durch diese Unterlassung von Bestätigungen entstehen indirekte Aufforderungen an die sendende TCP-Station Sendungen zu wiederholen, denn diese setzt für jedes gesendete Datenpaket einen TimeOut (eine Auszeit). Läuft dieser ab, ohne dass eine Bestätigung dafür eingegangen ist, dann sendet sie das Datenpaket erneut. In den nächsten Absätzen wird auf dieses Verfahren noch genauer eingegangen.
Die Datenpakete, die aus dem Bytestrom der Anwendungsdaten gebildet werden, werden jeweils durch Kontroll- und Steuerdaten ergänzt und Segmente genannt. Ein Segment besteht also aus einem Teil des Anwendungsdatenstroms zusammen mit einem Zusatz, der Segmentkopf oder TCP-Protokollkopf oder TCP-Header genannt wird. Unter anderem ist die bereits erwähnte Prüfzahl (chksm) in einem Segmentkopf enthalten. Für die Darstellung eines Segments wird anstelle einer Grafik oft eine linearisierte Schreibweise benutzt. Bei ihr wird das Segment in eckige Klammern gefasst. In der Klammer werden auf der linken Seite die für die aktuelle Diskussion relevanten Felder des Segmentkopfes - und nur diese - samt ihrer Werte angegeben, während auf der rechten Seite anstelle der Anwendungsdatenbytes ihre Anzahl aufgeführt wird. Als Beispiel betrachte man das folgende Segment:
Es transportiert 53 Bytes an Anwendungsdaten, und die Prüfzahl für dieses Segment ist 9256. Die Schreibweise chksm=9256 bedeutet nicht, dass im Segmentkopf die Zeichenfolge "chksm=9256" steht, sondern, dass sich im Segmentkopf ein Feld namens chksm mit einer bestimmten Größe befindet, dessen Inhalt die Zahl 9256 ist. Bei manchen Segmenten ist der Anwendungsdatenbereich leer. Solche Segmente transportieren nur Kontrollinformationen. Bei der linearisierten Schreibweise wird dafür anstelle von 0 bytes data kurz no data notiert.
Das Protokoll TCP hat eine voreingestellte maximale Segmentgröße von 536 Bytes. Allerdings können die beiden miteinander kommunizierenden Anwendungen davon abweichen und eine andere maximale Segmentgröße vereinbaren. Üblicherweise liegt der vereinbarte Wert bei 1024. (Um diese Größenvereinbarung nachvollziehen zu können, muss ein kleiner Vorgriff auf Protokolle der DoD-Ebenen 2 und 1 erfolgen: Die beiden TCP-Anwendungen versuchen, Segmente auszutauschen, die, ohne dass sie aufgeteilt werden müssen, in ein Paket des Vermittlungsprotokolls passen. Das ist fast immer IP. Und IP-Pakete werden sehr oft in einem Ethernet-Paket befördert, das höchstens ungefähr 1500 Bytes an Nutzdaten (das sind Daten ohne Protokollkopf) tragen kann.)
Die folgende Darstellung zeigt, dass die Byteströme von und zu den Anwendungen als Segmente transportiert werden:
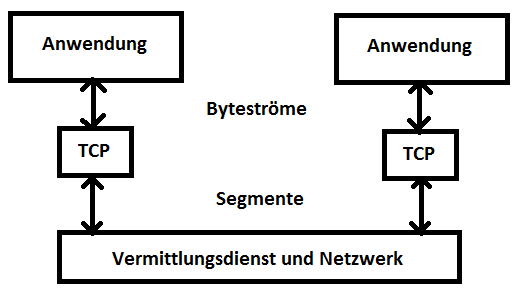
Segmente werden unabhängig voneinander transportiert. Im Internet ist es möglich, dass Segmente sich überholen können. Sie können auch verloren gehen oder dupliziert werden. Damit die empfangende TCP-Station aus den ankommenden Segmenten den ursprünglichen Anwendungsbytestrom rekonstruieren kann, müssen die Nummern der Bytes, die von dem Segment transportiert werden, im jeweiligen Segment festgehalten werden. Dazu gibt es im Segmentkopf ein Feld namens seq, dessen Wert die laufende Nummer des ersten Anwendungsdatenbytes ist, das zu diesem Segment gehört. Die Nummern der anderen Anwendungsdatenbytes in dem Segment ergeben sich durch Abzählen der Bytes.
Der Wert des Segmentkopffeldes seq heißt Sequenznummer. Es ist eine positive 32 Bits große Zahl, d.h. sie stammt aus dem Bereich der ganzen Zahlen zwischen 0 und 232-1. Ist beim Durchnummerieren der Anwendungsdatenbytes der Nummernraum erschöpft, wird zyklisch weitergezählt. Das ist eine Zählung mod 232-1. Das folgende Beispiel, bei dem die Prüfzahl keine Rolle spielt, zeigt einen 102 Bytes langen Ausschnitt aus einem Anwendungsdatenbytestrom. Der Ausschnitt ist in drei Segmente eingeteilt worden:
Das erste hier gezeigte Segment hat die Sequenznummer 50 und transportiert 30 Bytes an Anwendungsdaten. Das sind die Bytes mit den Nummern 50 bis 79. Das zweite Segment transportiert die nächsten 27 Anwendungsdatenbytes, also die Bytes Nummer 80 bis 106. Daran schließt sich unmittelbar das dritte Segment an.
Im obigen Beispiel ist mit der Nummerierung der Bytes des Anwendungsdatenstroms bei 0 begonnen worden. Man nennt dies eine kanonische (naheliegende) Nummerierung. Im Internet ist mit ihr ein Problem verbunden, denn angenommen, eine Anwendung erzeugt einen Datenstrom, beendet ihn und erzeugt einen neuen. Dann kann es vorkommen, dass der erste Strom oder Teile von ihm noch gar nicht zugestellt werden konnten, während bereits der zweite transportiert wird. Werden alle Datenströme kanonisch nummeriert, dann können auf der Empfängerseite Zuordnungsprobleme auftreten.
Um die geschilderten Zuordnungsprobleme zu minimieren, ganz beseitigen kann man sie nicht, wird die Zählung der Bytes mit einer zufällig gewählten Zahl aus dem Bereich 0 bis 232-1 begonnen. Sie heißt Anfangssequenznummer (Initial Sequence Number) und wird kurz als isn bezeichnet. Zu ihr gehört kein Feld des Segmentkopfes, sondern sie ist der Anfangswert des seq-Feldes und muss der empfangenden TCP-Station mitgeteilt werden. Das geschieht bei der Übertragung des jeweils ersten Segments zu einem Strom an Anwendungsdatenbytes. Dieses erste Segment transportiert noch keine Anwendungsdaten und sieht immer folgendermaßen aus, wobei für isn die jeweilige konkrete Anfangssequenznummer steht: