Das Internet ist ein logisches Netzwerk (vgl. Abschnitt 5.1 (Aufgaben eines Vermittlungsprotokolls)), dessen logische Adressen IP-Adressen genannt werden. Neben ihnen gibt es im Internet einen zweiten Namensraum, nämlich die Domänennamen, die bereits im Abschnitt 3.3 (Domain Name System) vorgestellt worden sind. Da alle Internetprotokolle intern mit IP-Adressen arbeiten, wird hier auf Domänennamen nicht weiter eingegangen.
Ein Teil der IP-Adressen wird von der zentralen Adressvergabeeinrichtung des Internet, der Internet Assigned Numbers Authority (IANA), nicht vergeben. Diese Adressen beginnen mit ganz bestimmten Bitkombinationen und heißen private IP-Adressen. Sie erlauben den Aufbau nicht öffentlicher Netzwerke mit Internet-Technologie. Alle anderen IP-Adressen sind öffentlich. IP-Pakete mit privaten Zieladressen werden von Routern nicht ins Internet vermittelt.
Bislang ist in der Lehrveranstaltung der Begriff IP-Adresse stets so verwendet worden, als handle es sich lediglich darum, mit einer solchen Adresse einen Rechner im Internet zu identifizieren. Aber der Adressbegriff im Internet ist wesentlich umfassender. Zum einen werden durch IP-Adressen keine Rechner, sondern Geräteschnittstellen zum Internet, angesprochen, und zum andern können mit ihnen auch Gruppen solcher Geräteschnittstellen adressiert werden. Von einer Rechneradresse darf im Grunde genommen nur dann gesprochen werden, wenn der Rechner genau eine Geräteschnittstelle zum Internet besitzt. Im Allgemeinen kann ein Rechner jedoch mehrere solche Schnittstellen und damit auch mehrere IP-Adressen haben. Es ist der Einfachheit der Darstellung geschuldet, wenn im Folgenden, dem üblichen Sprachgebrauch folgenden, von Rechnern und nicht von Geräteschnittstellen gesprochen wird. Beispiele für Rechner mit mehreren IP-Adressen sind die Router. Sie haben für jedes Netzwerk, an das sie angeschlossen sind, eine IP-Adresse. Ein Beispiel für eine Rechnergruppe ist die Gesamtheit aller Rechner in einem bestimmten Netzwerk. Sie alle können mit einer einzigen IP-Adresse angesprochen werden. Klassifiziert nach ihrer Verwendung gibt es die folgenden drei Arten von IPv4-Adressen:
Mit Unicast-Adressen werden einzelne Rechner (Geräteschnittstellen zum Internet) adressiert, mit Broadcast-Adressen alle Rechner in einem bestimmten Netzwerk und mit Multicast-Adressen eine Gruppe von Rechnern, die sich in unterschiedlichen Netzwerken befinden können. Alle drei Verwendungsarten werden in diesem Abschnitt etwas näher betrachtet.
Bei der Festlegung der IP-Adressen hat man sich für eine Adresslänge von 32 Bits entschieden. Damit stehen 232 = 4.294.967.296 (über 4 Milliarden) Bitmuster zur Verfügung, die als Adressen genutzt werden können. Üblicherweise wird eine IP-Adresse als Folge von 4 Bytes geschrieben, wobei jeder Bytewert dezimal (von 0 bis 255) angegeben wird. Als Trennzeichen wird zwischen die Bytewerte jeweils ein Punkt (Dot) gesetzt. Beispielsweise ist
eine IP-Adresse. Gespeichert werden die 32 Bits großen Muster selbstverständlich ohne die Punkte. Die Kombination aus IP-Adresse und Portnummer adressiert eine Anwendung auf einem bestimmten Host. Viele Anwendungen akzeptieren deshalb eine modifizierte Adressschreibweise, bei der die Portnummer, getrennt durch einen Doppelpunkt, hinter die IP-Adresse geschrieben wird, wie in dem Beispiel:
Mit dieser Angabe wird eine Anwendung angesprochen, die auf dem Rechner mit der IP-Adresse 89.241.5.146 mit dem Port 80 verbunden ist.
Unicast-Adressen bestehen aus zwei Teilen. Ihr anschaulich linker Teil identifiziert ein Netzwerk aus dem Netzwerkverbund des Internet, während ihr anschaulich rechter Teil einen Rechner in dem links angegebenen Netzwerk benennt. Die Vermittlungsrechner (Router) arbeiten mit dem linken Adressteil. Je systematischer dieser aufgebaut ist, desto einfacher wird die Vermittlung der IP-Pakete. An dieser Stelle wird deutlich, dass die Struktur von Adressen eng mit der Paketvermittlung (dem Routing) verbunden ist. Anschaulich hat eine Unicast-Adresse folgende Form:
Die Frage, wo in einer Unicast-Adresse die Trennung zwischen Netz- und Hostkomponente zu ziehen ist und wie das erkennbar gemacht werden soll, wurde zunächst durch die Festlegung sogenannter Adressklassen beantwortet. Sie spielen heute keine Rolle mehr, tauchen aber immer wieder in Beschreibungen auf und werden hier nur aus historischen Gründen vorgestellt. Eingerichtet wurden 5 Klassen mit den Bezeichnungen A, B, C, D und E. Bei den Klassen A, B und C wurde genau an einer der Bytegrenzen einer Adresse zwischen Netzkomponente und Hostkomponente getrennt und zwar folgendermaßen:
Neben diesen drei Klassen wurden noch zwei weitere eingerichtet, die mit D und E bezeichnet wurden. Die Klasse D enthielt die Multicast-Adressen, von denen jede mit dem Bitmuster 1110 beginnt. Das ist die einzige Adressklasse, die auch heute noch vorhanden ist. Allerdings wird nicht mehr von Klasse-D-Adressen gesprochen, sondern nur noch von Multicast-Adressen. Auf diese Adressart wird am Ende dieses Abschnitts noch kurz eingegangen. Klasse-E-Adressen beginnen mit dem Bitmuster 11110 und waren für experimentelle Zwecke vorgesehen.
Alle IP-Adressen an unserer Hochschule beginnen mit der Dezimalzahl 141. Hexadezimal ist das die Zahl 8D. Das heißt, dass alle unsere IP-Adressen mit der Bitkombination 10 beginnen und damit Klasse-B-Adressen wären.
Die Einteilung der Unicast-Adressen in feste Klassen erwies sich sehr schnell als unflexibel und wurde nicht lange beibehalten. Deutlich wird das insbesondere bei der Adressklasse A. Bei ihr beginnt jede Adresse mit einer 0. Aber die Hälfte aller 32 Bits großen Muster beginnt mit einer Null. Das heißt, dass 50% aller IP-Adressen Klasse-A-Adressen waren. Mit ihnen aber konnte man nur relativ wenige Netze adressieren, wobei sich in jedem dieser Netze eine riesige Anzahl von Rechnern befinden konnte. Das ging weit am Bedarf vorbei. Ähnliches, wenn auch nicht ganz so grass, gilt auch für die Klasse-B. Lediglich die Klasse C war recht nahe am tatsächlichen Bedarf.
Um den durch die Adressklassen gegliederten IP-Adressraum flexibler nutzen zu können, wurde etwa ab 1985 die zweistufige Einteilung von Unicast-Adressen in eine Netz- und eine Hostkomponente durch eine dreistufige Einteilung in eine Netz-, eine Subnetz- und eine Hostkomponente ersetzt. Dabei wurde die ursprüngliche Hostkomponente der IP-Adresse aufgeteilt:
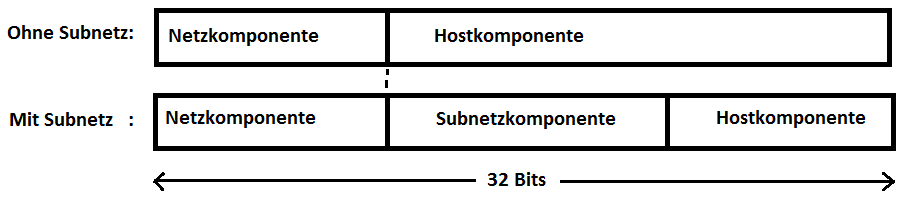
Die Adressklassen A, B und C trennen Adressen exakt an einer Bytegrenze. Ein Subnetz endet jedoch in der Regel innerhalb eines Bytes. Um diese Grenze zu markieren, wurde jeder IP-Adresse ein 32 Bits großes Muster zugeordnet, das Subnetzmaske genannt wurde. Es enthält auf allen Positionen, die bei der zugehörigen IP-Adresse zum Netz oder zum Subnetz gehören, eine Eins und auf den Positionen der (neuen) Hostkomponente eine Null:
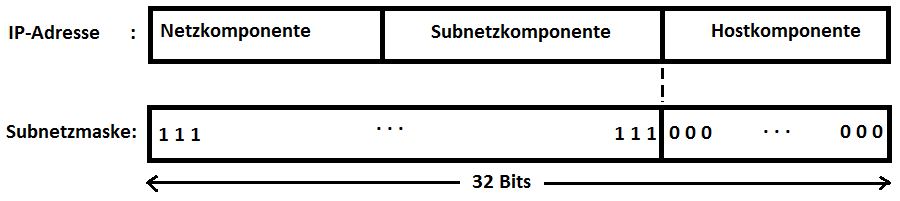
Im nächsten Schritt, so ab 1993, wurde das Konzept der Adressklassen ganz aufgegeben und der gesamte öffentliche IP-Adressraum (mit Ausnahme der Multicast-Adressen), dem Konzept der Subnetze folgend, hierarchisch gegliedert. Aus den Subnetzmasken wurden Netzwerkmasken, wobei viele Internet-Werkzeuge weiterhin den Begriff Subnetzmaske verwenden. Bei Netzwerkmasken gibt die Zahl der Einsen (von links gezählt) die Länge der Netzkomponente einer Unicast-Adresse an, die Zahl der darauf folgenden Nullen die Länge der Hostkomponente. Um jetzt von einer IP-Adresse feststellen zu können, zu welchem Netz sie gehört, muss eine Netzwerkmaske herangezogen werden. Jeder Router blendet mit solchen Masken (per logischem UND) die für ihn relevanten Netzwerkkomponenten aus den Zieladressen aus. Dieses Verfahren wird als Classless InterDomain Routing (CIDR) bezeichnet.
Wegen der üblichen byteweisen Dezimalschreibweise von IP-Adressen und Netzwerkmasken sind meistens weder die Netz- noch die Hostkomponente einer Adresse sofort ersichtlich. Man betrachte das Beispiel:
Um die beiden Adresskomponenten zu erkennen, müssen Adresse und Maske binär geschrieben werden:
Erst jetzt wird ersichtlich, dass die Netzkomponente durch die ersten 25 Bits der Adresse beschrieben wird und noch das erste Bit des letzten Adressbytes belegt, während für die Hostkomponente nur die rechtesten 7 Bits der Adresse bleiben.
Mit CIDR ist eine Schreibweise eingeführt worden, die das Erkennen der Netz- und der Hostkomponente einer IP-Adresse für den menschlichen Leser einfacher macht. Die Router allerdings müssen weiterhin die Netzwerkmaske heranziehen. Bei dieser sogenannten CIDR-Schreibweise wird die Anzahl der Einsen in der Netzwerkmaske durch einen Schrägstrich getrennt hinter die Adresse gesetzt. Das Beispiel von eben lautet damit folgendermaßen:
Das Suffix gibt an, wie viele Bits der IP-Adresse (von links gezählt) zu ihrer Netzwerkkomponente gehören.
Die CIDR-Schreibweise wird auch benutzt, um ganze Adressbereiche anzugeben, üblicherweise solche Adressbereiche, die zu Netzwerken gehören. Beispielsweise steht
für die Bitmuster von 141.64.0.0 bis 141.64.255.255 und beschreibt den IP-Adressraum unserer Hochschule. Nicht ganz korrekt, aber weit verbreitet ist bei dieser Schreibweise das Weglassen der rechten Nullen:
Die Festlegung, dass ein bestimmtes Bitmuster keine Adresse, sondern ein Adressbereich ist, hat zur Folge, dass dieses Bitmuster dann auch nicht als Hostadresse benutzt werden kann. Das heißt, dass durch
nur der Adressbereich
definiert wird.
Sowohl unter Linux- als auch unter Windows-Rechnern gibt es eine Kommandoschnittstelle, mit deren Hilfe die lokalen Adressinformationen abrufbar sind. Es sind die Shell-Kommandos
Bei meinem Windows-Rechner im Labor an unserer Hochschule beispielsweise wird mit ipconfig unter anderem ausgegeben:
Mit einer Broadcast-Adresse werden alle Rechner eines bestimmten Netzwerks angesprochen. Als IP-Adresse wird dafür die mit Einsen zu einem 32 Bits großen Muster ergänzte Netzwerkkomponente einer Unicast-Adresse aus diesem Bereich verwendet. Das Netzwerk
beispielsweise hat die Broadcastadresse
Damit kann diese Adresse wie schon die Adresse 141.64.0.0 ebenfalls nicht als Hostadresse verwendet werden. Das heißt, dass für Unicast-Adressen in dem 141.64/16-Netzwerk lediglich die Adressen
zur Verfügung stehen.
Rechner im Internet können unabhängig von ihrer Zugehörigkeit zu bestimmten Netzwerken zu Gruppen zusammengefasst werden. Die Gruppenbildung wird dadurch erreicht, dass allen Rechner einer Gruppe die gleiche Multicast-Adresse zugeordnet wird. IP-Pakete, adressiert an eine solche Adresse, werden jedem Gruppenmitglied zugestellt. Das Vorgehen bedarf einer Regelung, das heißt, es bedarf eines Protokolls. Weit verbreitet ist das Internet Group Management Protocol (IGMP), das aus Zeitgründen hier nicht weiter behandelt wird. Es soll genügen, darauf hinzuweisen, dass Multicast-Adressen mit der Bitkombination 1110 beginnen, denen eine durch das Protokoll festgelegte Gruppenkennung folgt. Das heißt, dass Multicast-Adressen Klasse-D-Adressen wären, wenn es noch Adressklassen gäbe.
Diese Adressart wurde eingerichtet, um Audio- und Video-Streaming zu unterstützen. Mit Streaming wird eine Technik bezeichnet, bei der mit dem Abspielen einer Audio- oder Video-Datei bereits begonnen wird, bevor die Datei vollständig übertragen ist.
Es gibt einige 32 Bits große Muster mit spezieller Bedeutung. Zwei von ihnen sollen hier vorgestellt werden. Das erste ist das Muster
Diese Adresse kann sich ein Rechner geben, solange er noch keine netzwerkspezifische Unicast-Adresse hat. Das ist beispielsweise dann der Fall, wenn er an einem Netzwerk gestartet wird und nicht über eine fest eingetragene Unicast-Adresse verfügt, sondern darauf wartet, dass ihm eine zugeteilt wird. Diese spezielle Adresse kann immer nur Quell- und niemals Zieladresse eines IP-Pakets sein, und kein Router vermittelt Pakete mit dieser Zieladresse.
Die Zuteilung einer Unicast-Adresse erfolgt durch das Dynamic Host Configuration Protocol (DHCP). Es ist ein Anwendungsprotokoll, das UDP als Transportprotokoll verwendet. Voraussetzung ist, dass es in dem lokalen Netzwerk, in das ein Host neu aufgenommen werden soll, einen DHCP-Server gibt. Der neue Host gibt sich zunächst die spezielle IP-Adresse 0.0.0.0 und liest seine MAC-Adresse aus. Damit wendet er sich per Broadcast an den DHCP-Server, der ihm nicht nur eine IP-Adresse, sondern auch eine Netzwerkmaske, ein Standardgateway und einen Namensserver zuweist.
Als zweites Beispiel soll der Adressbereich
(Die zugehörige Netzwerkmaske ist 255.0.0.0) betrachtet werden. Er beschreibt die IP-Adressen eines speziellen Netzwerks namens localnet, das meistens als Loopback-Netz bezeichnet wird. Dieses Netzwerk besteht einzig und allein aus dem lokalen Rechner und ist nicht mit einer Netzwerkschnittstelle verbunden. Pakete, die an eine Loopback-Adresse geschickt werden, können nur Anwendungen auf dem lokalen Rechner erreichen. Dieses Loopback-Netz wird für Entwicklungsarbeiten zur Verfügung gestellt. Beispielsweise können damit ein Client und ein Server auf ein und demselben Rechner entwickelt werden. Die Adresse
aus dem Loopback-Bereich ist die Broadcast-Adresse in dem Netzwerk localnet. Der lokale Rechner selbst wird localhost genannt und üblicherweise mit der Adresse
angesprochen, die als Loopback-Adresse bezeichnet wird. Allerdings kann jede Adresse von 127.0.0.1 bis 127.0.0.254 als Loopback-Adresse verwendet werden.
Öffentliche IP-Adressen werden von der bereits erwähnten Internet Assigned Numbers Authority (IANA) in großen Blöcken und hierarchisch strukturiert an sogenannte Regional Internet Registries (RIRs) vergeben, von denen es weltweit nur fünf gibt. Für Europa, den Nahen Osten und Zentralasien ist ein RIR namens Réseaux IP Européens Network Coordination Centre (RIPE NCC) zuständig. Ein RIR vergibt Teile der ihm zugewiesenen Adressen ebenfalls hierarchisch strukturiert an sogenannte Local Internet Registries (LIRs). Das sind üblicherweise Internet Service Providers (ISPs) wie beispielsweise die deutsche Telekom.
Bereits im letzten Jahrzehnt des vergangenen Jahrhunderts wurde deutlich, dass frei verfügbare IP-Adressen knapp geworden waren, was unter anderem zu der Entwicklung eines Nachfolgeprotokolls für IPv4 mit einem wesentlich größeren Adressraum geführt hat, nämlich zu IPv6. Der Druck, diesen Nachfolger einzuführen, wurde und wird noch immer allerdings durch die Technik der Adressübersetzungen stark abgemildert. Bei dieser Technik, die unter der Bezeichnung Network Address Translation (NAT) bekannt ist und in mehreren Varianten vorliegt, erhalten alle Rechner in einem üblicherweise lokalen Netzwerk IP-Adressen aus dem privaten Adressbereich des Internet. IP-Pakete mit solchen Zieladressen dürfen nicht ins Internet gelangen. Bei kleineren Netzwerken wird dafür häufig der Bereich
verwendet. Einer der Rechner des Netzwerks wird ausgezeichnet und erhält neben seiner Netzwerkschnittstelle zu dem Netzwerk mit den privaten IP-Adressen eine weitere zum Internet. Er arbeitet als Router und hat zwei IP-Adressen, nämlich eine private und eine öffentliche. Dieser ausgezeichnete Rechner wird oft als Proxy (Stellvertreter) bezeichnet. Nur er ist vom Internet aus erreichbar, und jeder Datentransfer zwischen Rechnern des privaten Netzwerks und dem Internet wird über ihn geleitet. Das heißt, dass er über alle Kommunikationsverbindungen, die über ihn laufen, Buch führen muss. Bei der NAT-Variante Port-mapped-NAT versieht er jede über ihn laufende Kommunikationsverbindung mit einer laufenden Nummer, die NAT-Port genannt wird. Er führt dynamisch eine Tabelle der folgenden Form, mit deren Hilfe er eingehende IP-Pakete den Anwendungen im privaten Adressbereich zustellen kann:
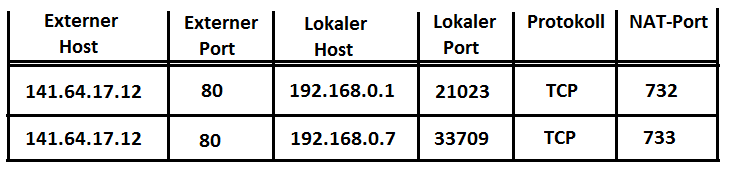
Bei der durch diese Tabelle beschriebenen Situation kommunizieren zwei Anwendungen im privaten Bereich auf den Rechnern mit den Adressen 192.168.0.1 und 192.168.0.7 mit ein und demselben Webserver am Port 80 des Rechners mit der öffentlichen IP-Adresse 141.64.17.12.
Adressübersetzungen sind einschränkend, denn die Kommunikation mit einer Anwendung im Internet muss von einem der Rechner mit privater IP-Adresse eröffnet werden. Ein Rechner im Internet kann einen Rechner im privaten Netzwerk nicht direkt erreichen. Vom Internet aus ist nur der Proxy ansprechbar.